前面写了一篇笔记介绍Hystrix中用到的设计模式,今天我们就一起看一下Hystrix是如何应用command来实现它的功能的。
Hystrix到底是什么呢?
简单讲,Hystrix是个提供延迟和容错机制的库,通过隔离分布式环境中对各种服务的依赖的方式,提高整个系统的健壮性。
这句话里提到的分布式一词,就是Hystrix针对的主要场景了。在分布式系统中,一个服务通常依赖于多个其他服务,其他服务又依赖于更多的服务。各个服务之间的依赖关系很可能是错综复杂的,如果不能恰当处理服务之间的依赖关系,那么很可能某一个服务挂了,就会导致任何依赖于它的服务都挂,这样的系统是十分脆弱的。
Hystrix就是为了解决这个问题而出现的~
Hystrix的主要功能
- 隔离:为每个服务依赖维护一个单独的线程池或者通过信号量来限制调用分布式服务的资源,避免个别服务出现问题时对其他服务产生影响。
- 超时:为每个服务设置一个timeout值,使得任何请求超时都在可控范围内,而不会一直傻等下去。
- 熔断(Circuit-breaker):但请求失败率达到一定值时打开熔断器,触发快速失败(Fail fast)。
- Fallback:在请求失败时调用fallback逻辑,比如可以提供默认值或者从缓存中返回一些数据等。
- 实时监控:Hystrix自带了一个monitor dashboard用于实时监控请求的情况
下图是Hystrix wiki上的官方流程图,可以看到所有这些机制都被融进了整个请求从发起到响应的整个流程中:
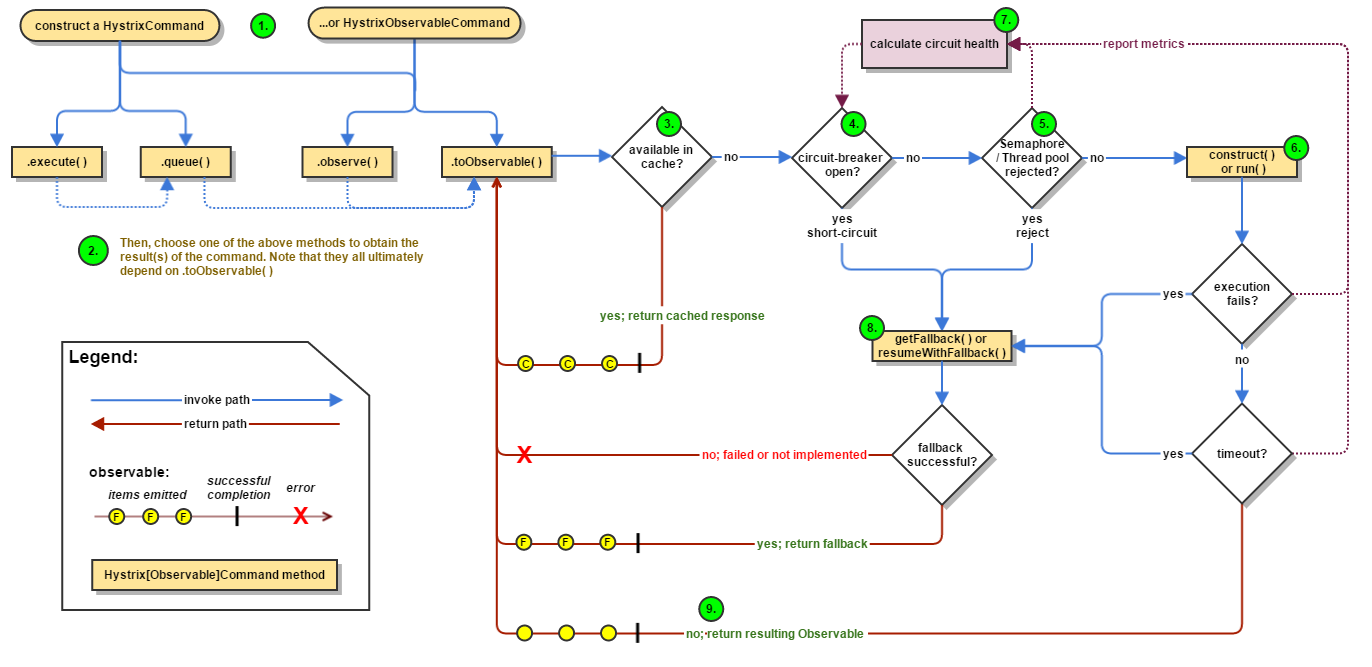
关于Hystrix的应用,它的Wiki上的介绍十分详细了,我就不再照搬啦。之前写过一个非常简单(逻辑完全是为了测试而写的)例子,跟spingboot集成的,放在GitHub上了,代码请戳spring-boot-hystrix-example
一些奇怪的关注点
为什么既有GroupKey又有ThreadPool?
(这一点其实想写这篇笔记的初衷了,感觉在设计上是可以借鉴的点。)
Hystrix默认是使用GroupKey为Command划分线程池的,也就是说属于同一个GroupKey的Command请求都会使用同一个线程池中的资源。那既然这样了,为什么还需要单独设置ThreadPool呢?
单独指定线程池的好处在于可以把资源与业务逻辑分开管理。比如说,我们希望某些Command在业务逻辑或者功能上是属于同一个Group的,但是在具体Command执行时,它们分别针对不同的资源进行处理。那么这个时候为它们单独划分线程池就可以提高资源的利用率。
官方举例如下:
假设有command A和command B都用来访问视频的元数据,GroupKey都是”VideoMetadata”,但是Command A访问资源#1, Command B访问资源#2。
这时如果command A请求过来,并且占用了线程池最后一个可用线程,这时又来了command B的请求,线程池饱和,command B就被卡住了,但其实它们俩真正要操作的资源是不冲突的,A本不应该阻碍B的。
上面这种情形,通过分别为A和B设置单独的线程池就可以避免啦~
Thread Pools vs. Semaphores
使用线程池最主要的代价就是线程的创建、排队、调度和上下文切换引入的计算开销。
如果请求延迟本身非常低(比如大部分请求操作可能直接从内存缓存中读取数据),那么切换线程带来的开销占比就太高了,在这种情况下可以选择使用Semaphore。
不过需要注意的是,semaphore不支持timeout,如果一个使用semaphorege隔离的依赖卡了,那么它的父线程会被阻碍住直到底层网络超时。
If a dependency is isolated with a semaphore and then becomes latent, the parent threads will remain blocked until the underlying network calls timeout.
Semaphore rejection will start once the limit is hit but the threads filling the semaphore can not walk away.