迟迟没有动手整理这一部分的内容,因为即使磕磕绊绊最终写出了一个勉强能用的爬虫,也是基于“拿来主义”在各大神的代码基础上拼凑出来的,其中还有很多知识点并没有弄懂。后来再查资料细看也十分痛苦。现在写记录的这些大部分还是一知半解的知识,暂且罗列在这儿,待有时间慢慢咀嚼。
下面进入正文。
按照爬虫(一)和爬虫(二)写好之后的代码,能开始爬数据了,打开数据库看一下口碑文章的具体内容,一阵悲伤袭来,为什么是不完整的!
对比在浏览器里看到的内容,明明都是好好的,怎么取到的数据就变成断断续续的了呢?这究竟是怎么回事?
审查元素了解一下。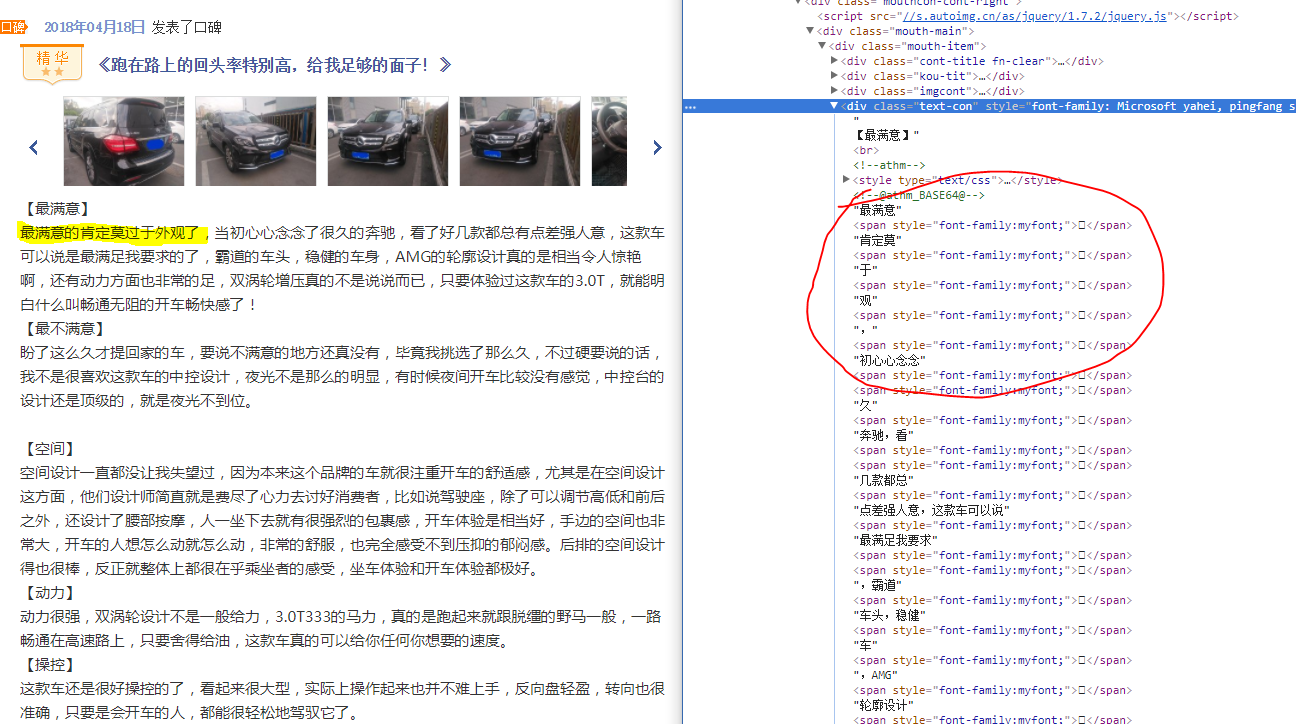
从上面的截图可以看到,对于浏览器显示出的一句看起来很正常的文本,其实在html文件中有不少文字都被<span>标签包住了:
1 | <span style="font-family:myfont;"></span> |
而且里面是一个不能正常显示的字符编码。这是什么操作?
注意到这些span标签的共性,都被赋予了一个css属性font-family:myfont,那么这个应该就是突破口了。
CSS自定义字体
隐约记得以前用过css自定义字体,把两个关键字CSS自定义字体 反爬放在一次在google搜了一下,没想到一下子就找到了相关的反爬介绍。感谢前辈们!
在审查元素里查找@font-face,可以找到类似如下的代码段:

在这个页面里,定义了一个叫myfont的自定义字体,每次打开页面时,浏览器会从src字段定义的地址下载这个字体用于当前页面的渲染。而这个字体文件,也是随机变化的,所以在爬的时候每次都要重新下载字体。
顺便简单了解一下TTF(TrueType)字体文件吧,不然再看其他人的博客时也晕乎乎的。
使用FontCreator打开从上文截图中那个URL下载下来的字体,内容如下:

这个字体文件给部分汉字赋予了自定义unicode,例如下面这个不可见字符,可以在word中得到其unicode编码ED57,再对应上图中编码为ED57的字形,就得到了“的”这个字。1
2<!--中间这个框框的unicode就是ED57-->
<span style="font-family:myfont;"></span>
对css自定义字体有了基本的了解之后,反反爬思路就有了:
- 下载当前页面的自定义字体
- 替换自定义字体编码
具体在Python中操作字体文件时可用fonttools库, 部分代码如下:
1 | from fontTools.ttLib import TTFont |
这样,css自定义字体反爬坑就算是趟过去了,总结一下几个相关知识点:
- css自定义字体
@font-face - 两个工具:
- 字体查看工具FontCreator
- Python字体操作库fonttools
好了,css字体我们也替换过了,这下爬下来的内容应该没问题了吧。哎,所以说我还是图样图森破啊!
加上了字体替换,还是不管用,就要濒临放弃的时候决定再仔仔细细看一遍网页源码。欸,有猫腻!

如上图所示,内容部分的标签里有不少<!--@athm_js@-->注释的<script>代码块,看起来就很可疑。展开之后是一串明显经过处理的js代码。想必定是它们对页面又做了手脚,继续google。
还好,又找到了前辈们的经验分享,不然真的要束手无策了。
可以想见,在浏览器加载了html文件之后,会在前端运行这些js代码,而这些js代码呢,对原始获取的html页面做了一定的处理,最后变成呈现在用户眼前的页面。

如上图高亮所示,可以推断这些js做的一部分事情就是把原装html中的某些部分替换成用span标签包裹的自定义字符。
而到目前为止,我们用代码爬取到的页面并不会像在浏览器中加载一样运行其中的js代码,因此直接对其做css替换并不能得到想要的结果。
找到病因就知道接下来该做什么了。
用PyV8运行js
爬虫是用Python写的,那么最先想到的方式就是在Python中运行js代码来模拟浏览器的操作。Python正好也有这样一个库PyV8提供了在Python中运行js的环境。
安装PyV8
PyV8是一个用Python封装V8引擎的壳,使得能够在Python中构建js的运行时环境。这个库历史久远,而且目前也不怎么有人在维护了,只支持Python2.X,所以为了使用PyV8这个库,原本这个爬虫项目是基于Python3.X都全部改成了2.X (:з)∠)
但是呢,在安装的过程中,也折腾了好一会儿。最后找到了一个比较靠谱的github仓库,安装过程参考这篇博客pyv8安装记录。命令如下:
1 | apt-get install -y libboost-all-dev |
使用PyV8
PyV8的文档找了很久也没找到什么,在项目中用的代码也是在前辈的代码上稍作修改就用起来了。代码主体来自博客Python爬去最新饭爬虫汽车之家口碑。
在copy了大神的代码之后,爬虫终于可以获取到完整的数据了。开心到飞起来!真的是非常非常感谢愿意分享经验的前辈们了!
然鹅,还没有飞出两米,又双叒叕掉坑里了。
在爬虫跑起来之后,发现爬不了几个页面就会挂,查看log发现报了Segmentation Fault的错。排除之后发现这个问题是由PyV8造成的,内存没来得及及时释放什么的造成了溢出。继续Google,把各种奇奇怪怪的解决方案都试了一下,最终找到了一个不再出错的方式。(吐槽:PyV8没有正式文档,而且各种版本都靠开源大神们的贡献真的用起来很捉急_(:з)∠)_
解决方案来自PyV8 segmentation fault with CherryPy。修改后的部分代码如下所示:
1 | from bs4 import BeautifulSoup |
上面这段代码对js的处理我还没太看懂_(:з)∠)_,大概是在混淆后的js中添加了一部分代码获取到了要替换的十六进制数字,然后顺便搞定了自定义字体替换。
再次给大神们笔芯!♥
组装好所有的代码之后,再跑爬虫时,终于能work了!
遗留问题
在本系列的最开头就说过这只爬虫仍然是一只有缺陷的虫子,主要残疾是由汽车之家的用户验证机制导致的。频繁访问多个口碑页面之后,服务器会重定向到一个用户验证页面,在浏览器打开这个页面时,会被要求输入验证码,有的时候是拼图形式,有的时候是按顺序戳汉字形式。
实在是没有精力再继续研究这玩意儿了,所以在实际跑爬虫的时候,基本上只能算是半自动,每次爬到被墙的时候,就要手动戳开浏览器输个验证码什么的_(:з)∠)_
唉,到底还是缺陷儿。
结束语
终于,爬虫难产之旅系列到这里就结束啦。虽然最终产物仍然不够完美(还应该更好的,到底还是被畏难心理打败了)。复盘一下整个过程,虽然还遗留了不少疑惑,但比之前又get了很多。剩下的坑,等哪天搞定了心理建设再继续吧~
代码请戳 → autohome-spider
爬虫系列: