在上一篇文章中,基于Scrapy的爬虫的架子已经搭起来了,满心欢喜以为虫子能跑起来了,结果发现高兴得太早噢~
写程序没有bug那还有什么乐趣?与八阿哥斗,其乐无穷啊!下面,就来看看八阿哥都使出了哪些招数吧~
Headers
即使网站的页面都是对公众开放随意访问的,但是对于原始数据,很多网站如果没有公开API那就是不愿意轻易让大家获取的了。对于基本的robot或是真实用户的访问,通过HTTP请求的header字段判断是最简单的方式。
当然啦,这一招也很好拆招,不过也需细心。有可能有时漏掉一两个字段就会拿不到数据哦。
以访问URL: https://k.autohome.com.cn/detail/view_01bz95vp0d64w30e9h70sg0000.html 为例,打开开发者窗口,查看浏览器发送请求时所带的headers。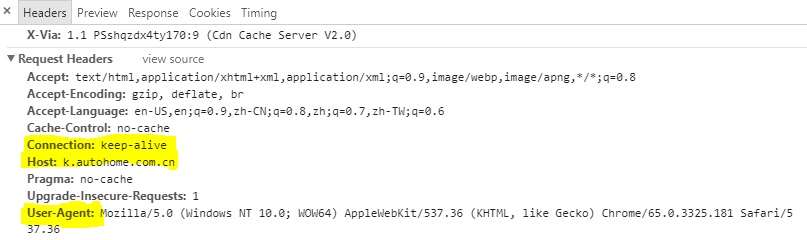
如上图所示,将浏览器带的headers依葫芦画瓢加到代码里。上面高亮的几个字段单独拎出来聊一聊。
Host:k.autohome.com.cn- 给出接收请求的服务器的主机名和端口号,可以是域名也可以是IP地址;在HTTP/1.1中,Host字段是必须要有的,HTTP/1.0的话则有木有都可以。User-Agent:...- 这一长串是非常重要的伪装了~一只聪明的虫子要懂得假装自己是个使用浏览器访问页面的好奇乖宝宝哦~(题外话,关于这一长串背后的故事曾经看到过一篇非常可爱的文章《浏览器野史列传》,很有意思~)
因为在请求头中对User-Agent进行伪装几乎是爬虫必要操作,Scrapy也提供了便捷的支持,只需三步:在settings.py文件中打开
USER_AGENTS配置,示例如下:1
2
3
4# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENTS = [
# 这里可以放多个常用User-Agent,随便搜索一下copy过来就可以啦
]在middlewares.py中新增一个类,比如就叫RandomUserAgent,在其process_request方法中添加随机选择一个User-Agent设置到请求头中的逻辑,代码如下:
1
2
3
4
5
6
7
8
9
10
11
12class RandomUserAgent(object):
"""Randomly rotate user agents based on a list of predefined ones"""
def __init__(self, agents):
self.agents = agents
def from_crawler(cls, crawler):
return cls(crawler.settings.getlist('USER_AGENTS'))
def process_request(self, request, spider):
request.headers.setdefault('User-Agent', random.choice(self.agents))在settings.py中的
DOWNLOADER_MIDDLEWARES中加入新建的RandomUserAgent中间件,配置如下:1
2
3DOWNLOADER_MIDDLEWARES = {
'autohomeSpider.middlewares.RandomUserAgent': 1
}完成以上三步,就可以每次发请求时,都会从配置好的User-Agent列表中随机挑一个添加到请求头中,假装是不同的用户用不同浏览器上浏览页面的效果。
Connection: keep-alive-这个字段对于这个爬虫是可有可无的,但是也是比较有用的一个字段。 HTTP/1.1允许TCP连接在完成一次事务处理后保持在打开状态,以便为之后的HTTP请求重用现存的连接,这样就大大降低了建立连接的资源和时间开销。keep-alive表示客户端请求将连接保持在打开状态,如果服务器同意,则在响应头中也会有一条相同的header,但在HTTP/1.0+中它并不是默认使用的,因此请求头中必须显式指明。HTTP/1.1不再支持keep-alive连接,而改用持久连接(persistent connection)取而代之,HTTP/1.1下持久链接默认就是激活的,如果要在事务处理后关闭连接,则需要显式添加一条Connection:close。(emmmmmmm……这部分HTTP/1.0和1.1的历史遗留问题还挺多的,详情可以戳《HTTP权威指南》第四章连接管理,讲得很详细。)
至于其他固定值的headers,可以直接写在上文提到的已经创建好的爬虫FeedbacksSpider类中,每次发请求时将其作为headers参数传入就可以了。
Redirect
用浏览器访问口碑详情页(以 https://k.autohome.com.cn/detail/view_01bz95vp0d64w30e9h70sg0000.html 为例)时,观察页面加载过程,我们会发现先有一次302重定向,然后有一次307重定向,然后才是200成功加载页面。
302/303/307 傻傻分不清
当时看到302和307都是重定向,就去查资料,结果还蹦出来个303,那么他们之间到底有什么区别呢?
下面是RFC2616里对302/303/307的定义:
302 Found - The requested resource resides temporarily under a different URI. Since the redirection might be altered on occasion, the client SHOULD continue to use the Request-URI for future requests. If the 302 status code is received in response to a request other than GET or HEAD, the user agent MUST NOT automatically redirect the request unless it can be confirmed by the user, since this might change the conditions under which the request was issued.
303 See Other(Since HTTP/1.1) - The response to the request can be found under a different URI and SHOULD be retrieved using a GET method on that resource. This method exists primarily to allow the output of a POST-activated script to redirect the user agent to a selected resource.
307 Temporary Redirect(Since HTTP/1.1) - The requested resource resides temporarily under a different URI.Since the redirection MAY be altered on occasion, the client SHOULD continue to use the Request-URI for future requests. If the 307 status code is received in response to a request other than GET or HEAD, the user agent MUST NOT automatically redirect the request unless it can be confirmed by the user, since this might change the conditions under which the request was issued.
303与302/307的不同之处就在于若原始请求是POST,那么服务器返回303并给出新URL,期望客户端向重定向URL发送一个GET请求(也就是客户端自己做主改变了操作类型,把POST变成了GET)。
而看起来302和307根本就一样嘛,都表示当前URL访问的资源被临时移除,并在response中给出重定向的地址,如果原始请求是GET/HEAD之外的操作,则客户端重定向时要向用户再次确认是否进行与原始请求同样的操作(以免带来副作用)。
那为什么还会出现两个状态码呢?主要就是因为HTTP/1.0和HTTP/1.1两个规范针对同一行为使用两个不同的状态码。(HTTP/1.0[RFC1945]中的302和HTTP/1.1[RFC2616]中的303)定义重了。
在RFC2616对302的解释中还有这么一段:
RFC 1945 and RFC 2068 specify that the client is not allowed to change the method on the redirected request. However, most existing user agent implementations treat 302 as if it were a 303 response, performing a GET on the Location field-value regardless of the original request method. The status codes 303 and 307 have been added for servers that wish to make unambiguously clear which kind of reaction is expected of the client.
为了解决重复的问题,HTTP/1.1规范指出,对于HTTP/1.1客户端,用307状态码取代302状态码来进行临时重定向。这样服务器就可以将302状态码保留起来,为HTTP/1.0客户端使用了。
cookie不能丢
写好爬虫第一次启动时,就掉进了一个坑。从浏览器访问口碑详情页完全没问题,但是用scrapy访问的时候,就拿不到页面了,好奇怪。
也是因为对HTTP请求访问不熟悉,用抓包工具大概折腾了一天,很仔细的对比了浏览器访问和用命令访问的请求过程,问题就出现在上一节提到的重定向过程里。
再来仔细看看第一次302响应头里的内容: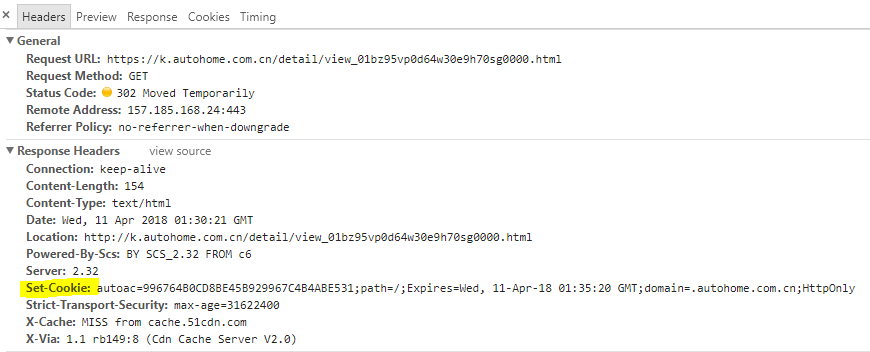
这里高亮部分Set-Cookie非常重要,它里面包含了一个autoac值,看起来是个token之类的东西,总之如果丢了这个,之后即使重定向也不能正常拿到页面了。
我们可以用curl命令看看详细的过程,以如下命令为例:1
curl -L -v -b -i 'https://k.autohome.com.cn/detail/view_01bz95vp0d64w30e9h70sg0000.html'
参数说明:
-L开启重定向,否则会直接返回302的结果,不会再继续访问重定向URL-b也是这个问题的关键了,允许将之前收到的响应头中的Set-Cookie的值加到后续请求头中-i,-v主要是为了查看请求头和响应头。
调用结果部分截图如下,可以看到第二次的重定向请求带上了cookie,这样服务器就会再次重定向回原URL,最终获取到页面。如果不带-b参数,就会重定向循坏,最终被服务器判断为爬虫,重定向到用户验证界面结束。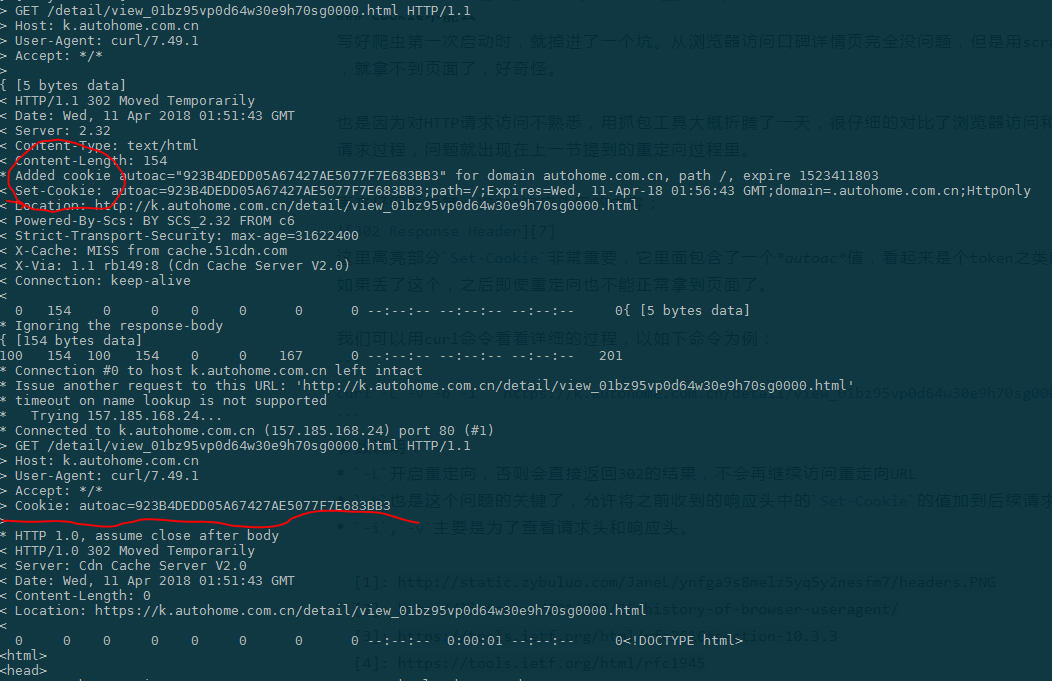
找到根本原因了,再来看看在Scrapy里我们要怎么修改代呢?
Scrapy默认不会处理非2xx的响应,因此跑之前的代码会导致什么都拿不到,为了让scrapy的spider处理30x在FeedbacksSpider类中添加如下参数,然后scrapy就会帮我们做好重定向以及set cookie的工作了。(详细介绍参见Scrapy文档):1
2
3meta_no_redirect = {
'handle_httpstatus_list': [302, 404]
}
到目前为止,我们填好了几个小水坑,终于可以顺利拿到页面了,说好的爬取数据终于可以开始了呢!
无知的我尚未发现前方还有个巨大的坑早已挖好等我跳下去。
继续填坑之旅请戳 [一只爬虫的难产之旅(三)]