在这个阳光明媚的周末下午,我决定写一篇笔记纪念一下我写第二只爬虫的心路历程,毕竟苦苦挣扎了将近一个月呢。
以下为本人的碎碎念,看正文可直接跳过去下一小节了~
为什么是第二只呢,因为第一只虫子头脑简单四肢发达,顺利出生在狗年春节之前。那是在我还是一个彻头彻尾的爬虫小白的时候,在老司机们的推荐下用框架Scrapy以汽车之家-搜索文章页面为入口写了一个简单的以关键词为输入爬取搜索结果页面的爬虫,这个过程出人意料的顺利。
于是乎,一个愉快而美味的春节就这么过去了。
节后回来,得知根据需求还需要爬取更多的数据,日常挖坑坑自己的我挑中了汽车之家-口碑的数据。任务目标很简单,就是把口碑页面所有车系的所有口碑详细页面的内容爬取下来。
有了第一次的经验,这第二次还不是轻车熟路嘛。Scrapy这么好用,写个Item对应要存储的数据,写两个parse方法解析一下页面,保存一下,搞定!来,跑一下,欸欸欸欸?怎么翻车了???就这样,小狗仔爬虫的难产之旅就此开始。
就让我们从头回顾吧~
爬虫需求:爬取汽车之家口碑数据
爬虫思路 - Verson 1:
- 以口碑车系列表页 - https://k.autohome.com.cn为入口,获取所有车系列表页链接
- 爬取单个车系的口碑列表,获得口碑详情页链接(比如:奥迪A8怎么样 - https://k.autohome.com.cn/146)
- 爬取每个口碑详情页(比如:A8使用感受,超级无敌详细 - https://k.autohome.com.cn/detail/view_01c2dazamh64w3ae1n6wsg0000.html )
搭架子 - Scrapy是个好东西
由于时间比较赶,所以python爬虫的一些教程也都没有怎么仔细看过,就直接拿Scrapy上手了,真的很好用!
Scrapy是一个开源的python爬虫框架,不熟悉的朋友可以移步官方网站了解一下。
Scrapy项目建好后,项目目录如下所示:
定义数据结构 - 创建Item
在items.py里新增Feedback类继承自scrapy.Item类,里面定义了想要爬取的内容字段,其中items字段存储每篇口碑的文字内容,这里用的复数表示这是一个列表,因为口碑作者在发表了一篇口碑之后,还可以再追加口碑,追加口碑的格式跟第一篇口碑的格式差不多,因此都存储在了items这个字段里,将来作为一个list存入数据库。
存储数据 - 创建Pipeline
在这个爬虫项目中,我将爬取的数据存储在了MongoDB中,非关系型数据库用起来相当方便了~
要完成这一操作主要需要如下两步:
- 在settings.py中添加MongoDB的配置信息(这一步不是必须哒,如果你不想配settings,也可以直接硬编码啦)
- 在pipelines.py中新增FeedbackMongoPipeline类,在process_item方法中将item存入数据库。
创建spider
数据结构定义好了,存储也搞定了,现在就剩下最关键的一步——数据爬取。不要方,有了Scrapy,数据爬取也变得超简单~
在spiders文件夹下创建feedbacks_spider.py,里面定义FeedbacksSpider类继承自scrapy.Spider类,实现具体的爬虫逻辑。按照上文提到的爬虫思路,这个类主要定义了三个方法:
def start_requests
这是Spider类的入口方法,按照最初的思路,这个方法只需要返回一个Request,url=https://k.autohome.com.cn ,然后交给一个callback解析获取跳转到所有车系的link,但是实际操作时,我并没有这样做。在访问这个url时,我发现戳不同的筛选条件,网站都会发送一个ajax请求调用一个API,如下图所示: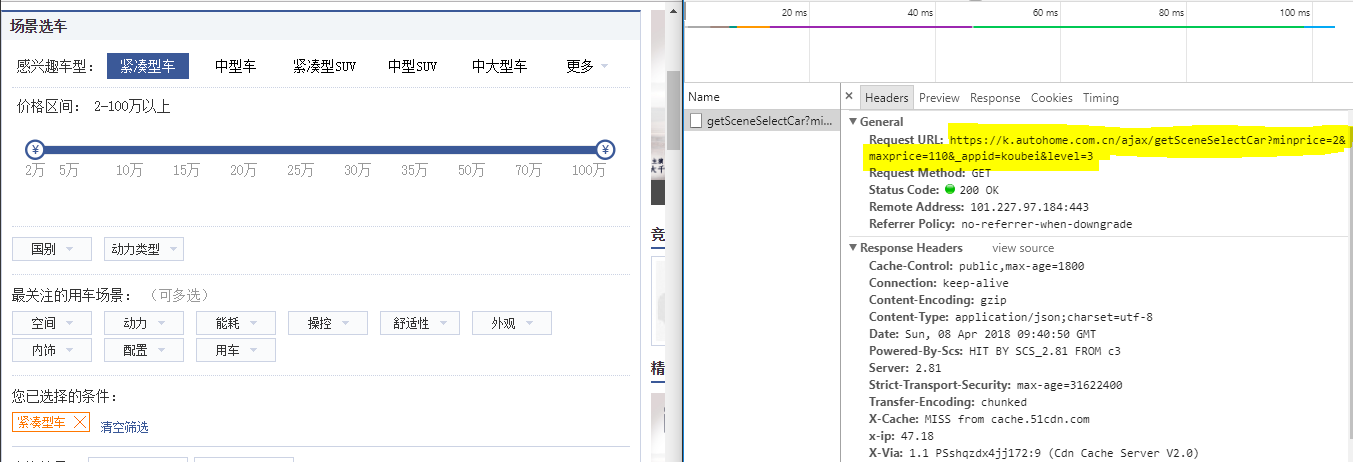
使用postman访问这个API-https://k.autohome.com.cn/ajax/getSceneSelectCar?minprice=2&maxprice=110&_appid=koubei&level=3 ,可以得到一个JSON对象,如下图所示: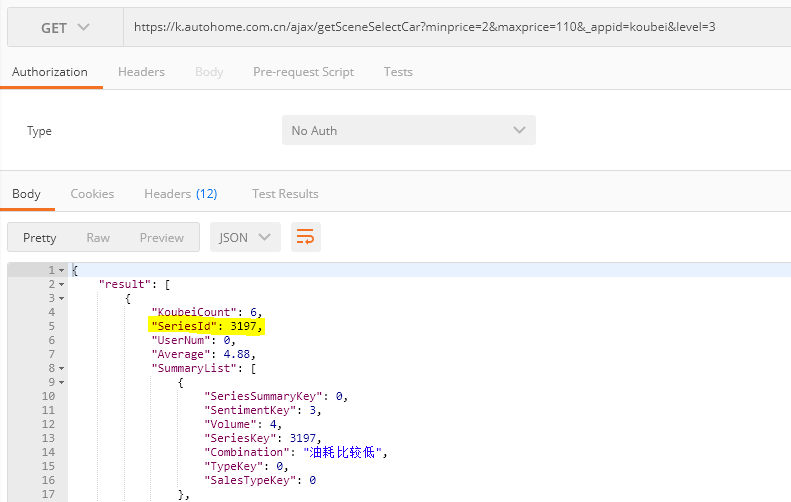
这是result是一个list,里面返回了全部符合筛选条件的车系的基本信息,你会发现,高亮部分的SeriesId对我们的爬虫非常有用,因为车系口碑列表页link长这样https://k.autohome.com.cn/{SeriesId}。
有了这个发现,我们就不需要先爬取口碑入口页,再解析这个页面获取车系列表页链接,更新后的爬虫思路-Version 2:
- 调用API获取所有车系的SeriesId
- 使用SeriesId拼接车系口碑列表页的link,爬取单个车系的口碑列表,获得口碑详情页链接
- 爬取每个口碑详情页
然而,这还不是最终版本的爬虫过程,因为V2版本是一个非常完美的过程,在爬取的每一步中我们都能顺利获取数据。而真正实现的时候,就无法忽视中途go die这种悲伤的事实了。比如每个车系的口碑列表页是分页的,有的车系有很多口碑,可能高达一两百页,如果爬到中间断掉了,照如上实现方式,只能从头来过。而还有,可能有的口碑详情页面访问失败了,数据没有爬取到,就丢失了。因此,为了解决上述两种失败情况,我在数据库中多定义了两个集合:
series_ids: 有两个字段,一个是id,一个是index。用途如下:
- 在爬虫初次爬取之前,调用API获取所有SeriesId存入数据库。
- 爬虫开始之后,如果某个车系的口碑全部爬取完成,即在解析时没有下一页了,则将此SeriesId从数据库中删除。
- 若爬取到某个车系口碑列表的第n页时,失败了,则将n存入数据库,下次重启爬虫时,直接从第n页开始爬取。
failed_detail_pages: 当爬取口碑详情页失败时,就将该详情页的id存入数据库,下次重启爬虫时,除了爬取列表页,也会重新爬取之前访问失败的详情页。
在不断改进之后,我们有了爬虫思路 - Version 3:
- 调用API获取所有车系的SeriesId并存入数据库
- 从数据库中读取SeriesId,根据id和index访问对应车系口碑列表页
- 若访问成功,获取口碑详情页链接,爬取口碑详情页数据,若访问失败,则将失败的详情页id存入数据库
- 若访问失败,将当前访问的列表页index更新至数据库
- 从数据库读取之前访问失败的口碑详情页,若此次访问成功,则爬取数据之后将id从失败列表中删除
综上,在start_requests中小蜘蛛们将会被分为两支队伍分别前进,一支爬取列表页,一支爬取之前失败的详情页,并分别交给以下两个不同的callback做解析。
Scrapy提供了两种解析页面的选择器,一种是CSS,一种是XPath。听说XPath效率会高一点,所以在项目中我用的是Xpath选择器。不熟悉XPath的话,在解析页面时可以借助一些工具,比如Chrome的插件SelectorGadget等。
def parse_feedback_list
这个方法用于解析列表页,在实际跑爬虫的过程中我发现如果访问过于频繁,汽车之家会重定向请求到一个用户验证地址(要填很随机的验证码,有时是拖动拼图,有时是按指定顺序戳汉字,就很迷(:з)∠),我还没有想出解决方案),这个列表页就算是访问失败了因此现在用的workaround就如前所述,将失败的index存储到数据库中,下次开启爬虫重新尝试访问。
这就要求用到SeriesId这个数据,Scrapy中在创建请求时提供了一个参数叫meta,用户可以自定义一些参数过来,这样获取到response对象后,可以从response.meta中读到之前传入的数据。
传入SeriesId示例代码如下:
1 | def start_requests(self, level=None): |
parse_feedback_list代码如下,其中有读取meta中的SeriesId:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21def parse_feedback_list(self, response):
# if this crawled page is redirected to user verify page and get response 200
if re.search(verify_page_regex, response.url):
index = re.search(index_regex, response.url).group(1)
db.series_id.find_one_and_update({'id': response.meta['series_id']}, {'$set': {'index': index}})
else:
# 在response对象的meta字段中就包含了request创建时传入的自定义参数
self.logger.info("Crawling feedback of car series: %s" % response.meta['series_id'])
# get the feedback list for the specific car series
links = response.xpath("//div[@class='mouthcon']//div[contains(@class, 'title-name')]/a/@href").extract()
for link in links:
yield response.follow(url=link, headers=self.headers, dont_filter=True, callback=self.parse_feedback_page, errback=self.errback_httpbin, meta=response.meta)
# go to next page
next_page = response.xpath("//a[@class='page-item-next']/@href").extract_first()
if next_page is not None:
yield response.follow(url=next_page, callback=self.parse_feedback_list, dont_filter=True, meta=response.meta)
else:
# if successfully crawled the whole list page of one series, then delete the series id from db
db.series_id.find_one_and_delete({'id': response.meta['series_id']})
简单介绍一下上面这段代码的逻辑吧(我觉得注释写得还算清楚哒:
- 首先对拿到的response.url进行判断,如果它已经重定向到了用户验证地址则更新数据库,放弃解析;否则,解析页面:
- 获取该页所有的详情页地址,创建请求,交给回调函数parse_feedback_page处理
- 检查是否有下一页,如果有,获取下一页列表地址,创建请求,回调函数仍然是parse_feedback_list;如果没有,则该车系口碑列表页爬取结束,从数据库series_ids里删除该车系id
def parse_feedback_page
这个方法就是用来解析口碑详情页的了,在这里会创建一个先前在items.py里定义好的Feedback对象,然后使用XPath解析页面,给对应的字段塞数据,全部塞好之后,返回这个对象。
然后Scrapy就会调用配好的Pipeline,流水走起来~
在本项目中只有一个Pipeline要走,就是将Item保存到数据库中~
这里多说一句,Scrapy的Pipeline配置可以配置在全局settings.py文件中,也可以给每个spider单独配Pipeline,这里我采用的是单独配置的方式,因为项目中写了多个spider(第一只那个头脑简单的spider也放在这同一个项目里了~),单独配置可以让每个spider走不同的流水线,彼此不影响。
单独配置Pipeline也很简单啦,给FeedbacksSpider类中加入如下字段:
1 | class FeedbacksSpider(scrapy.Spider): |
整个搭架子的过程看起来比较简单,作为小白还是get了一些经验滴。
- 着手解析页面之前,除了审查元素看页面结构之外,看看页面的加载过程很有用,一方面说不定能发现可以直接调用的API,能拿到现成的结构化数据就再好不过了;另一方面,也能了解页面是否有用到ajax等异步加载方式,对后续页面的解析也会有影响的。
- 不要只想着直接拿现成的URL,用参数拼接URL也是很可取的方式。
- 用户验证真的是一个很让人头大的问题啊(爬虫与反爬真的是相爱相杀=。=
到此为止,如果不出意外的话,应该爬虫就可以工作起来了,然鹅,事情远没有那么简单(此处应有表情包),坑,这才算是刚刚准备好了。
欲知坑在何处,能否顺利填坑,请移步:
代码都放在Github上了,两只爬虫因为都是爬的汽车之家,所以放在同一个Scrapy项目里了。老二其实到现在也没有能完全自由行动,还是时刻需要人盯着。
难过。