在前一篇笔记中我们总结了网络层的拥塞控制机制,主要以检测拥塞并及时反馈拥塞为主,毕竟要想控制拥塞,还得从根本上解决 —— 减缓传输层的发送速率以减少传输层注入到网络层的流量。
换言之,我们希望采用某种拥塞控制算法能为传输层找到一种好的带宽分配方法,这种分配方法具备如下特质:
- 物尽其用 - 能利用所有可用带宽却能避免拥塞
- 一视同仁 - 为网络中相互竞争的流是公平地分配带宽
- 随机应变 - 能及时跟踪流量需求的变化,并快速收敛到公平且有效的带宽分配上。
理想的带宽分配
下面我们就来展开聊聊传输层的“理想型”吧~
输入负载与实际吞吐量
下图描述了拥塞发生的过程,横坐标表示输入负载 (offered load) —— 即原始数据加上重传的传输速率,纵坐标表示实际吞吐量 (throughput) —— 即传递原始数据的速率。
可以看到,在到达网络的承载极限之前,实际吞吐量随输入负载的增加而增加,然而,随着输入负载接近网络的承载能力,偶尔突发的流量填满了路由器的缓冲区,造成丢包。这些丢失的数据消耗了部分容量,并且会引起重传,因此送达的数据低于理想曲线。如果这个时候还不控制输入负载,那么最终网络会被重传的数据包占领,导致实际吞吐量急速下降,出现拥塞崩溃 (congestion collapse)。
相应的,在输入负载提升的初期,延迟稳定在一定水平,表示穿过整个网络的传输延迟。随着负载接近临界,延迟逐步上升,最终演变为急剧上升。
因此,我们希望一个好的拥塞控制算法能有效控制输入负载,在避免导致拥塞出现的情况下,最大程度发挥所有可用带宽的作用,是为“物尽其用”。
最大-最小公平性
抛开采用服务质量要求网络预留带宽的情况,理想情况下,路由器应该为所有的连接公平地分配带宽,即如果有 N 个流同时使用同一条链路,那么每个流应该拥有 1/N 的带宽。
然而,真实情况要复杂的多,要做到一视同仁可不是一件容易的事。
不同的流经过不同的路径,这些路径各自的容量也不同,有可能一个流在下行链路上被阻塞,并且在上行链路获得比其他流更小的流量,此时减少其他流的带宽来实现所谓上行链路带宽分配的公平并没有任何益处。
因此,在网络中,带宽分配的公平以最大-最小公平 (max-min fairness)为原则。所谓最大-最小公平,指的是如果分配给一个流的带宽在不减少分配给另一个流的带宽的前提下无法得到进一步增长,那么就不给这个流更多的带宽。
看起来很拗口,我们可以直观地思考一下,想象网络中所有的流都从速率零开始慢慢增加,当某个流的速率遇到瓶颈,就停止增加这个流的速率,所有其他的流继续增加各自的速率,平等共享可用流量,直到它们也达到各自的“瓶颈”。
TCP 的拥塞控制
接下来,就让我们一起来看看 TCP 协议作为传输层两大主力军之一,是如何围绕“理想型”的要求实现拥塞控制的吧。
TCP 采用的方式是让发送方根据感知到的网络拥塞的程度来限制它的发送速率。那么,问题来了:
- TCP 如何限制发送方的发送速率?
- TCP 如何感知到拥塞的发生?
- TCP 采用什么算法调整发送方的发送速率?
拥塞窗口
先回答第一个问题,TCP 如何限制发送方的发送速率。
我们都知道 TCP 连接的双方各自维护了一个接收缓冲区,一个发送缓冲区和一堆变量,其中有一个变量 —— 拥塞窗口 (congestion window),通常以 cwnd 表示,代表了任何时候发送方可以向网络中发送的字节数。除此之外,TCP 还有一个流量控制窗口 (receive window),通常以 rwnd 表示,代表了接收方当前能够缓冲的字节数。
那么,TCP 的发送方的允许发送的字节数取 cwnd 和 rwnd 的较小的值,即发送方的发送速率可以表示为如下公式,RTT 表示往返时延:
$$R_{trans} \le \frac{min\{cwnd, rwnd\}}{RTT}$$
拥塞检测
关于第二个问题,TCP 如何感知拥塞的发生。
我们已知丢包通常是拥塞发生的表现,TCP 作为一个可靠的数据传输协议,可以利用它的应答机制和计时器来判断是否发生拥塞。
TCP 将如下两种情况视为拥塞发生的征兆:
- 发生超时
- 收到三个重复的 ACK
拥塞控制算法
终于到了关键问题,TCP 到底是如何调整发送速率的?如果发送速率太高,将导致网络拥塞,而如果矫枉过正,发送速率太低,又降低了资源利用率,不能物尽其用。
TCP 的实现遵循如下几条原则:
- 当检测到拥塞时,发送方的发送速率应该降低。
- 收到应答意味着发送方之前发送的数据被接收方正常接收,说明网络没有拥塞,因此,当收到当前尚未应答的数据包的 ACK 时,可以提高发送速率。
- 带宽探测(bandwidth probing) - 根据上面两条,当收到 ACK 时 TCP 会提高发送速率,直到超时或者收到三个重复 ACK,这时就该降低发送速率了。因此 TCP 会一直处于在拥塞的边缘疯狂试探的状态,即一直提高速率直到感知到拥塞,然后降低速率,然后又开始提升速率,降低速率,…。实际上也就是在不断地探测拥塞即将发生的临界点,以达到“物尽其用”的效果。
基于以上原则,我们来看看 TCP 拥塞算法的具体细节,这个算法最早由 Van Jacobson 在 1988 年提出,在 RFC5681 中标准化。它包含四个主要组成部分:
- 慢启动 Slow-start
- 拥塞避免 Congestion Avoidance
- 快速重传 Fast Retransmission
- 快速恢复 Fast Recovery
慢启动
在建立 TCP 连接时,发送方用一个很小的值初始化 cwnd,最开始采用的是 1 MSS (Maximum segment size),2013 年增加到10 MSS。开始时,发送初始窗口大小的数据,每收到一个数据段的确认应答 cwnd 就增加 1 MSS。这个机制被称为慢启动 (Slow start),不过,它实际上一点都不慢——呈指数增长。以初始值为 1 MSS 为例,一开始发送方发送一个数据段,待收到确认应答后就能发送两个数据段,这两个数据段被应答后就能发送四个数据段…
那么,当指数增长到何时结束呢?根据不同的情况,TCP 有不同的决策:
- 如果发生超时,发送方将把
cwnd重置为初始值,相当于触发新一轮的慢启动;同时,它还会设置另一个变量ssthresh(slow start threshold, 慢启动阈值) 的值为cwnd/2(ssthresh的初始值为任意高)。ssthresh记录了上一次发生拥塞时的拥塞窗口的一半大小,这意味着当cwnd到达这个值时若还采取指数增长的模式,下一轮增长就跟上次发生拥塞的值一样了,很有可能又会导致拥塞。所以,当这种情况发生时,TCP 将切换到拥塞避免状态。
- 如果收到三次重复 ACK,TCP 会执行快速重传,并进入快速恢复状态。
慢启动限制了可用的吞吐量,对于小文件传输非常不利,比如针对一些短暂突发的连接,会出现还没有达到最大窗口请求就被终止的情况。
拥塞避免
当进入拥塞避免状态时,cwnd 从慢启动增长切换到线性增加,每个 RTT cwnd 的值增加 1 MSS。
一种常见的近似做法如下:每收到一个 ACK,cwnd 的值增加 MSS * (MSS/cwnd)。举个例子,假设 MSS 为 1460 字节,cwnd 为 14600 字节,那么每个 RTT 可发送 10 个数据段,每收到一个 ACK 增加 1/10 MSS,收到 10 个 ACK 增加 1 MSS,约等于一个 RTT 增加 1 MSS。
那么问题又来了,在拥塞避免状态时发生丢包怎么办?还是分两种情况:
- 如果发生超时,跟慢启动时一样,重置
cwnd为初始值,并设置ssthresh为发生超时时的cwnd的一半,并切到慢启动状态 - 如果收到三次重复 ACK,将
cwnd的值减半,并设置ssthresh为收到重复 ACK 时的cwnd的一半,并切换到快速恢复状态
快速重传 / 快速恢复
当收到三个重复 ACK 后,TCP 会根据这个 ACK 的序号推算出可能丢包的那个数据段,并立即重传,这种机制被称为快速重传。
在快速恢复状态下,每收到一个重复 ACK,cwnd 的值增加 1 MSS,直到收到了新的 ACK,这意味着接收方已经收到了之前一直没收到的数据段,TCP 会切回拥塞避免状态,并将 cwnd 的值设为 ssthresh 的值。
如果在快速恢复的状态下发生了超时,则跟前面两种状态一样,设置 ssthresh 为当前 cwnd 的一半,再重置 cwnd 为初始值,并切回慢启动状态。
下图是 TCP 拥塞控制的有限状态机:
想了解更详细的 TCP 拥塞机制,请戳RFC 5681。
值得一题的是,我们上述描述的 TCP 拥塞机制源于 TCP Reno,而在 Reno 之后,也出现了很多变种的 TCP,比如 TCP NewReno, CUBIC TCP, TCP Vegas, TCP BBR等等,感兴趣的可戳TCP Congestion Control
AIMD
TCP 的拥塞控制通常被称为 AIMD 控制算法。AIMD 是 Addictive Increase Multiplicative Decrease 的缩写,即加法递增乘法递减。
AIMD 被证明是能达到有效和公平性的最优店的流量控制规则,详见 Chiu, Dah-Ming; Raj Jain (1989). Analysis of increase and decrease algorithms for congestion avoidance in computer networks。
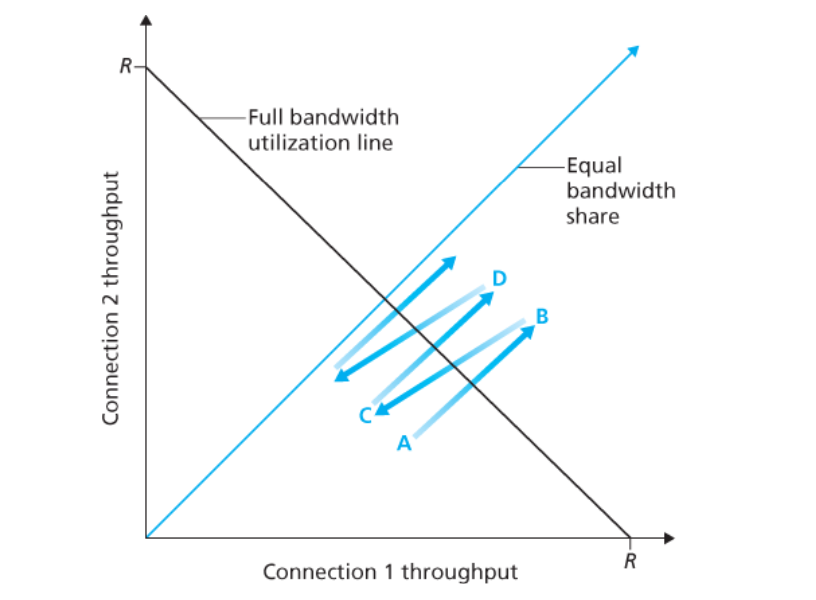
如上图所示(图取自 Computer Networking A Top-down Approach 7th),黑线表示效率,蓝线表示公平性。假设有两个连接共用一条链路,在某一时刻网络中两个连接的吞吐量处于图中 A 点状态,此时网络带宽还有盈余,两个连接加法递增各自的带宽,当到达 B 点时,网络负载超载,出现拥塞,双方占用带宽减半,到达 C 点,这时带宽又出现富余,双方带宽再次加法递增,达到 D 点,…,如此往复,这种行为的轨迹最终将收敛到兼顾效率与公平的平衡点。
拥塞控制并不是一件容易的事情,时至今日,针对日益变化的网络形态,很多学者仍在研究的更优的拥塞控制算法,以上内容也不过浅尝辄止罢了。
参考资料
- Computer Networking: A Top-Down Approach, 7th Edition
- 计算机网络,第五版
- RFC 5681
- TCP Reno and Congestion Management